Diseño de un Esquema Estrella
Como se había mencionado en un post anterior, un modelo dimensional se implementa en una base de datos relacional como un esquema estrella. Un esquema estrella permite realizar los siguientes cambios sin afectar ninguna aplicación o consulta existente:
- Es posible aumentar medidas siempre que sean consistentes con el nivel de detalle de la tabla de hechos.
- Es posible aumentar nuevas tablas de dimensión siempre que esta no altere el nivel de detalle de la tabla de hechos.
- Es posible aumentar atributos a una tabla de dimensión.
- Se puede incrementar el nivel de detalle aumentando atributos a una tabla de dimensión, ajustando la tabla de hechos (si es necesario y teniendo cuidado de no cambiar los nombres de las columnas en las tablas de hechos y dimensión. Por ejemplo, es posible cambiar el nivel de detalle de una instantánea periódica mensual a una instantánea diaria aumentando atributos (Ej, «dia_mes») a la tabla de la dimensión tiempo.
En términos generales, el proceso de diseño del esquema estrella incluye las siguientes actividades:
- Identificar el proceso de negocio
- Especificar el nivel de detalle (grain)
- Identificar las medidas
- Identificar las dimensiones
El propósito es identificar, a partir de los requerimientos de análisis y la compresión de los procesos de negocio, elementos tales como indicadores, medidas, nivel de detalle y dimensiones.
Tablas de hechos
Las tablas de hechos almacenan las medidas generadas por un proceso de negocio en columnas individuales y están vinculadas con las tablas de dimensión mediante claves foráneas; cada vez que el sistema operacional que soporta la ejecución del proceso de negocio registra transacciones, las medidas generadas deberán registrarse en la tabla de hechos correspondiente; estas tablas, a diferencia de las tablas de dimensiones, tienden a ser “profundas” más que “amplias” y son las concentran el mayor volumen de datos en un Depósito de Datos.
Aspectos comunes a todos los tipos de tablas de hecho son:
- Carácter exhaustivo. Deben incluir todas las métricas generadas por el proceso,[1] incluso si alguna de ellas es redundante, para evitar que cliente tenga que realizar operaciones al momento de realizar las consultas y así mejorar el desempeño; por ejemplo, además de las medidas “ingresos” y “gastos” debería incluirse la métrica “ganancia” (ingresos – gastos).
- Dispersión. Esto hace referencia al hecho de que las tablas no incluyen una fila para cada combinación de valores en sus dimensiones; dependiendo del tipo de tabla de hecho, estas pueden ser más o menos dispersas.
- Nivel de detalle. El nivel de detalle al cual van a ser almacenadas las medidas en cada fila está determinado por el máximo nivel de detalle de las dimensiones asociadas. Puede haber tablas con nivel de detalle transaccional o tablas agregadas.
Antes de describir las características de los distintos tipos de tablas de hechos es importante mencionar que en consideración de los requerimientos de análisis de una organización, es posible combinar características de estas tablas siempre el diseño asegure que todas las medidas incluidas se generen al mismo nivel de detalle.
Tabla de hechos transaccionales
Empleadas para el seguimiento de las transacciones generadas por un proceso. Aunque suelen tener un nivel de detalle transaccional (por cada transacción registrada en el sistema operacional hay una fila en la tabla de hechos) también puede ser agregado. Las medidas en estas tablas suelen ser aditivas y su dispersión alta. Una tabla de hechos para el proceso de ventas que tenga una fila por cada línea/ítem en la transacción es un ejemplo de este tipo de tabla de hechos.
Si el proceso de negocio genera también un medida a un nivel mayor al nivel de detalle de la tabla, el valor de esta medida deberá ser distribuido entre los ítems de detalle[2]; por ejemplo, si una venta incluye dos ítems (hay dos líneas en el recibo de venta) y además la venta implica un coste de envió, este coste deberá ser distribuido entre las dos líneas.
Tabla de hechos tipo instantánea periódica
Empleadas para medir el efecto de un serie de transacciones en un periodo de tiempo. Estos efectos usualmente se manifiestan en alguna medida que indica el nivel o estado de algún valor. El nivel de detalle está determinado por intervalo en el cuál se miden los efectos de las transacciones (cada hora, cada día, cada semana, cada mes, etc.). Las medidas de estas tablas sueles ser semi-aditivas y su dispersión baja debido a que es siempre posible obtener una medida de estado para un periodo aunque no se hayan producido transacciones. Una tabla para el seguimiento de balance de cajas de ahorro es un ejemplo de este tipo de tabla; en este caso por ejemplo, sin importar si se han realizado retiros o depósitos en un caja de ahorro esta tiene siempre un saldo al final de un periodo.
Tabla de hechos tipo instantánea acumulativa
Empleadas para capturar medidas y tiempos generados por eventos que ocurren en diferentes fases de un proceso (usualmente de tipo workflow). El nivel de detalle está determinado por la entidad objeto del workflow. A diferencia de otras tablas esta tabla permite actualización de las filas en la tabla de hecho a medida que se suceden las fases del workflow.
Una tabla para el seguimiento de la otorgación de un crédito es un ejemplo de este tipo de tabla; inicialmente, cuando la solicitud es aceptaba se inserta una fila en la tabla de hechos con dos medidas: “monto solicitado” y “monto desembolsado” (inicialmente con valor cero); en otro momento, el crédito es aprobado y se autoriza el desembolso lo cual se refleja actualizando la medida “monto desembolsado”.
Este tipo de tablas mantienen varias relaciones con la dimensión tiempo que reflejan los momentos en los cuales se ha registrado/actualizado alguna medida y suelen incluir medidas de duración desde el inicio del proceso hasta los eventos que provocan la actualización de las medidas.
Tabla de hechos sin hechos (factless)
Empleadas en situaciones en las que es necesario analizar un suceso de interés que vincula a instancias de las dimensiones pero no genera alguna medida. El nivel de detalle está determinado por el nivel detalle de las dimensiones cuyos vínculos interesa analizar. Al no existir una medida asociada, el único valor numérico que puede derivarse de este tipo de tablas es el conteo de ocurrencias.
Una tabla para registrar las visitas a una página web es un ejemplo de este tipo de tablas y la única medida resultaría de contar las visitas.
Tablas de dimensiones
Las tablas de dimensión almacenan información sobre el contexto del proceso al momento de generar una medida, típicamente describen el cuándo, dónde, quién, cómo y qué generó la medida. Todos los datos dimensionales que describen el mismo concepto/entidad deben ser agrupados en una tabla de dimensión; por ejemplo, el nombre y dirección del cliente deberían ser dos columnas en la tabla dimensional “cliente”; estas tablas, a diferencia de las tablas de hechos, tienden a ser más “amplias” que “profundas”.
Aspectos comunes a todos los tipos de tablas de dimensión son:
- Uso de claves primarias sustitutas. Las tablas de dimensión deben emplear claves primarias sustitutas; es una práctica común es emplear columnas auto-numéricas excepto para el caso de la dimensión tiempo en cuyo caso se suele emplear la fecha como tal o una representación numérica de la fecha.
- Deben incluir las claves primarias de origen cuando están asociadas a entidades en los sistemas operacionales.
- Deben incluir una fila para representar la ausencia o no aplicabilidad de la dimensión; esta fila se emplea cuando una medida no incluye algún elemento del contexto sea por que no aplica, o por algún problema en la calidad de los datos; por ejemplo, como un registro de venta sin un cliente asociado.
- Los nombres de las columnas y los valores almacenados deben ser lo más descriptivos posible y evitar al máximo el uso de códigos; por ejemplo, si el género de los clientes es importante, los valores deberían ser “FEMENINO” y “MASCULINO” es lugar de emplear algún tipo de codificación como “F” o “M”.
- No es recomendable que una dimensión (una columna en la tabla de dimensiones) tenga muchos valores; en el caso de valores numéricos como el salario, es recomendable crear bandas o categorías salariales para facilitar el análisis.
A continuación se describen algunas consideraciones de diseño y uso de tablas de hecho que se presentan con relativa frecuencia, para mayor información se recomienda estudiar las referencias bibliográficas.
Dimensiones con múltiples roles
Son tablas con las que la tabla de hechos puede tener más de una relación. Son muy comunes en las tablas de tipo instantánea acumulativa que suelen tener varias relaciones con la dimensión tiempo.
Dimensiones degeneradas
Datos dimensionales almacenados en la tabla de hechos.
Dimensiones basadas en comportamiento
Cuando medidas generadas determinan el valor de la dimensión. Por ejemplo, analizar el volumen de ventas de la pasada gestión por cliente y determinar si es un cliente “regular”, “importante” o “muy importante”.
Estrategias para gestionar el cambio en los datos de origen
Cuando se detecta un cambio del valor de un dato dimensional en el sistema operacional, dependiendo de los requerimientos de análisis y el dato modificado se suele aplicar alguna de las siguientes estrategias:
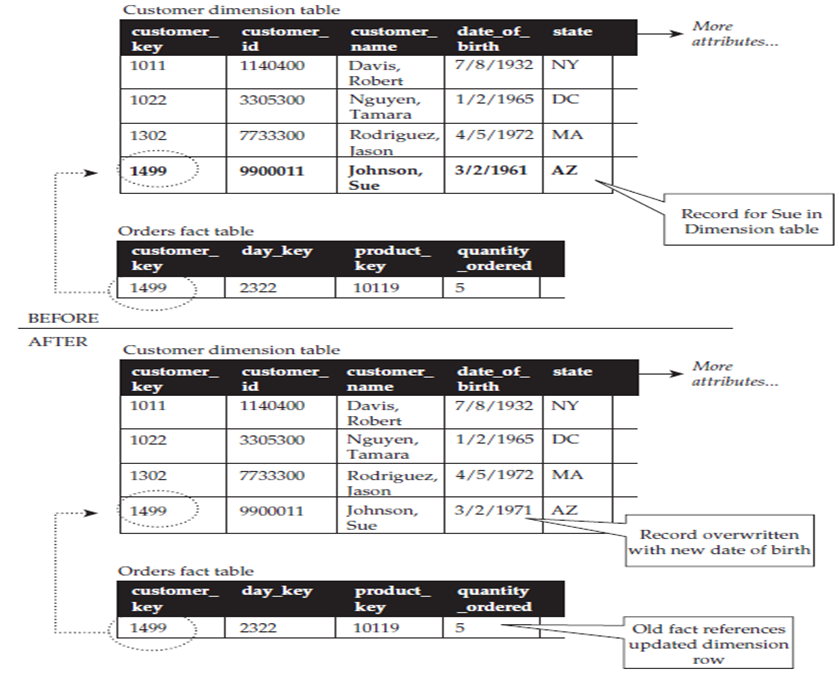
SCD I
El valor se sobrescribe en todas las filas de la tabla de dimensión que hacen referencia a la entidad cuyo dato ha cambiado. Con esta estrategia se cambia el contexto de eventos pasados y se aplica cuando no es necesario preservar el contexto histórico de hechos pasados como cuando se corrige algún error de entrada de datos (‘Peres’ -> ‘Perez’).
Ejemplo de SCD-I tomado de Star Schema. The Complete Reference:
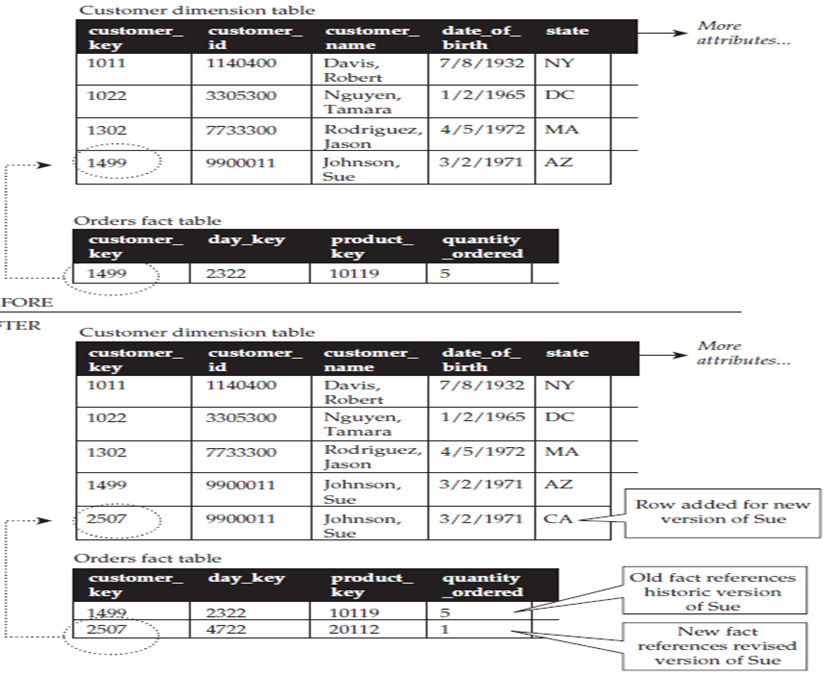
SCD II
En valor anterior se preserva y se inserta una nueva fila en la tabla de dimensión con el nuevo valor creando una segunda versión de la entidad en la tabla de dimensión. Cada versión de la entidad debe estar acompañada de atributos que permitan identificar el periodo de tiempo durante el cual una versión es válida de manera tal que las filas en las tablas de hechos, en función de cuándo sucedieron, se vinculen con la versión adecuada de la entidad en la tabla de dimensiones. Con esta estrategia se preserva el contexto de eventos pasados como cuando un cliente cambia de departamento/provincia y deseamos preservar, por ejemplo, ventas pasadas con la dirección vigente al momento de realizar las transacciones.
Ejemplo de SCD-II tomado de Star Schema. The Complete Reference:
En el siguiente vídeo se hace una demostración de cómo implementar este tipo de dimensiones con Pentaho Data Integration:
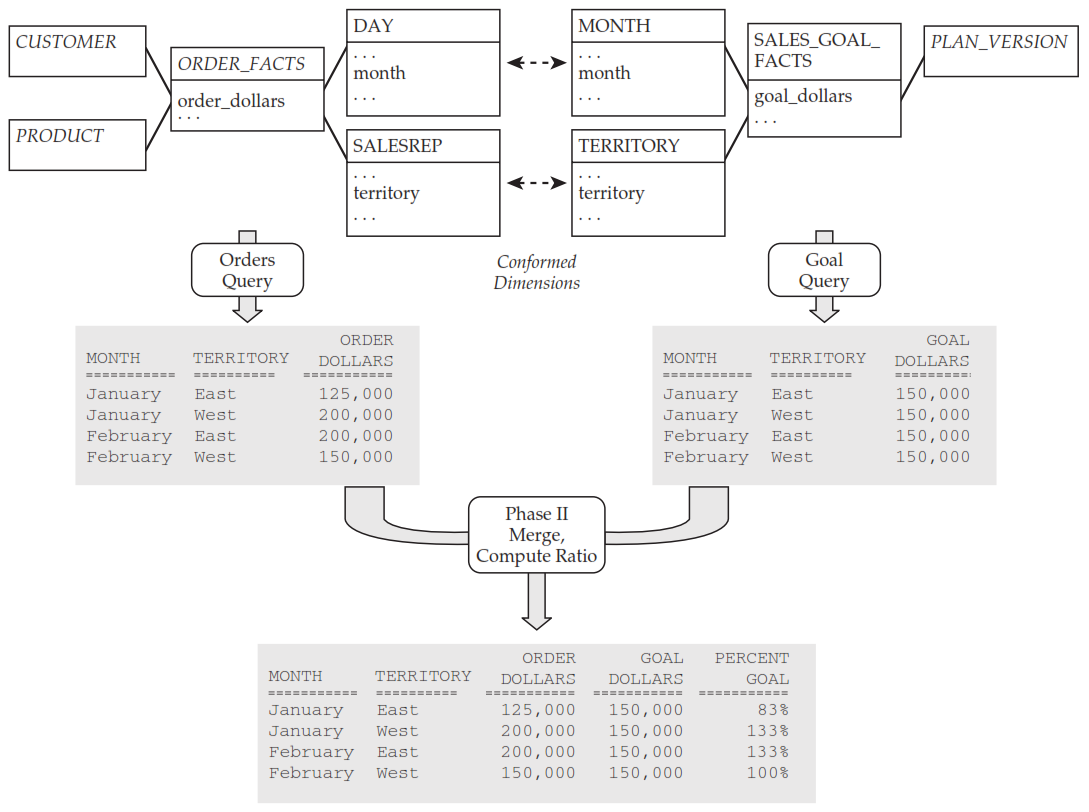
Dimensiones conformadas
Las dimensiones conformadas son dimensiones compartidas por dos o más estrellas (procesos) y son críticas para analizar de manera conjunta varios procesos con técnicas como drill-across. Si por alguna razón una dimensión en conformada es implementada en varias tablas, estas deberán incluir los mismo datos dimensionales (con la misma estructura y contenido). Mayores detalles sobre los requisitos que un par tablas deben satisfacer para considerarlas conformadas se pueden encontrar en la referencias bibliográficas.
Ejemplo de operación drill-across tomado de Star Schema. The Complete Reference:
Referencias
- [1] Kimball, Ralph (2013).The Data Warehouse Toolkit, Third Edition. Wiley
- [2] Adamson, Christopher (2010).Star Schema. The Complete Reference. McGraw-Hill
- [3] PostgreSQL Configuration Tool
[1] Exceptuando las métricas no aditivas.
[2] Esta técnica se conoce como “allocation”
Comments are closed.