Conceptos fundamentales
Dato, información y conocimiento
Dato
Un dato es un valor generado por un evento; por ejemplo, la venta de un producto puede generar como dato el valor del importe de la venta o el nombre del cliente que realizó la compra. Un dato tiene asociado un tipo; por ejemplo, el valor del importe de la compra es de tipo numérico, el nombre del cliente es de tipo textual; otros valores pueden ser de tipo lógico (verdadero/falso) o hacer referencia a una clasificación (alto, medio, bajo). El tipo asociado al dato determina las operaciones que se pueden realizar con él; por ejemplo, con los números, se pueden realizar sumas, obtener el mayor de un conjunto, sacar promedios etc. Los datos pueden ser atómicos o compuestos, es decir, pueden tener partes; por ejemplo, el importe de la venta es un valor atómico, el nombre del cliente podría considerarse que está formado por los nombres, el apellido materno y el apellido paterno.
Una operación determina el número y tipos de datos con los que puede operar, el resultado esperado y el tipo de dato del resultado; por ejemplo, la operación suma está definida para dos datos de tipo numérico y nos permite obtener otro dato de tipo numérico.
Finalmente, los datos, por sí mismos carecen de significado; por ejemplo, si alguien nos dice “50.30 Bs” o “Juan Perez Gonzales” estos mensajes carecen de significado.
Información
La información es un mensaje con significado usualmente resultante de la manipulación de los datos. La información también puede entenderse como datos en un contexto; por ejemplo, “Juan Perez Gonzales compró una bufanda en 50.30 Bs”
Conocimiento
Conocimiento es información que puede generar acción; es decir, información útil en un contexto determinado. Por lo tanto, la misma información puede ser conocimiento para una persona y para otra no; incluso para una misma persona y en función de una situación temporal específica la misma información puede ser o no considerada conocimiento.
Calidad de la información
Se considera que la información es de calidad cuando exhibe los siguientes atributos:
- Completa. No omite ningún elemento relevante de la realidad, por ejemplo, un reporte de ventas que no incluya la fecha podría considerarse incompleto.
- Confiable. Cuando refleja fielmente la realidad, por ejemplo, si un instrumento muestra que el promedio de ventas es de -100 Bs, tendríamos dudas sobre la fiabilidad de la información
- Oportuna. Debe estar disponible cuando se necesite.
Bases de datos
Una base de datos es una colección de datos relacionados entre sí, organizados de manera tal que se facilitan operaciones de manipulación de datos como la búsqueda y actualización; por ejemplo, el directorio telefónico. Cuando las Bases de Datos se almacenan en computadoras, la gestión de las mismas normalmente se realiza empleando un software especializado conocido como Sistema Gestor de Bases de Datos que provee un entorno conveniente y eficiente para la gestión de grandes volúmenes de datos almacenados de forma estructurada.
Dependiendo de la estructura en la que se organizan los datos y los mecanismos de gestión de datos, las bases de datos de clasifican en:
- Bases de datos relacionales. Los datos se estructuran en filas y columnas como en una hoja de cálculo y se emplea el lenguaje SQL como el mecanismo para gestión de datos.
- Bases de datos jerárquicas. Los datos se estructuran en jerarquías como en el organigrama de una empresa.
- Bases de Datos no-SQL. Este es un denominativo genérico que hace referencia a bases de datos que proveen estructuras de almacenamiento y mecanismos para gestión de datos diferentes de las Bases de datos relacionales.
Sistema de Información Operacional vs Analítico
Los sistemas de información (SI) pueden ser clasificados en dos grandes categorías:
- Sistemas Operacionales, centrados en facilitar la ejecución de procesos de negocio; estos sistemas emplean bases de datos con un diseño optimizado para facilitar la modificación concurrente de los datos.
- Sistemas Analíticos, centrados en el análisis del desempeño de los procesos; estos sistemas emplean bases de datos con un diseño optimizado para facilitar la flexibilidad y desempeño en la consulta de gran cantidad de datos.
Por ejemplo, un sistema que facilita el registro diario de cada venta estaría en la primera categoría; por otro lado, un sistema que facilita la comparación de las ventas de las diferentes sucursales con metas previamente establecidas estaría en la segunda. La diferencia en el propósito de ambos tipos de sistemas se ve reflejada en aspectos que van desde el usuario típico hasta el enfoque de diseño de las bases de datos que emplean.
La siguiente tabla resume algunas de las principales diferencias entre este tipo de sistemas:
| Operacional | Analítico | |
| Propósito | Ejecución de los procesos de negocio | Análisis del desempeño de los procesos de negocio |
| Usuario típico | Nivel operativo de la pirámide organizacional | Nivel táctico, Nivel estratégico |
| Interacción dominante | Insertar, Consultar, Actualizar y Eliminar | Consultar |
| Reportes | Estandarizados | Estandarizados y ad-hoc |
| Conocido también como | Sistemas transaccionales | Sistema de Soporte a la toma de decisiones |
| Diseño de la Base de Datos | Modelo Entidad – Relación normalizado (3FN+) | Modelo dimensional(Esquema estrella o Cubo) |
| Preservación de la profundidad histórica | No es un requisito | Es un requisito |
| Incluye datos de fuentes externas | No | Probable |
| La BD se conoce también como | BD TransaccionalBD fuente/origen | BD Gerencial/BD Analítica/Depósito , Almacén o Bodega de datos/ Data warehouse / Datamart |
Evolución de los Sistemas de Soporte a la toma de decisiones
Primera Generación: Consultas e informes generados en lote
Los primeros sistemas empleaban aplicaciones por lotes (batch) ejecutadas periódicamente para generar salidas impresas o archivos planos con los informes en los cuales los usuarios tenían que buscar las respuestas concretas a sus preguntas de negocio.
Estos sistemas generan sus resultados a partir de la consulta de complejas bases de datos operacionales y su manejo y actualización requería de conocimientos avanzados de acceso a datos y manejos de computadoras. Los consumidores de esta información, como ejecutivos de negocio y directores, muy difícilmente podían operar estos sistemas y mucho menos adaptarlos para responder nuevas preguntas de negocio.
Segunda Generación: Depósito de Datos
Esta generación de sistemas se caracteriza por reconocer que los datos almacenados en las bases de datos operaciones no son adecuados para le generación de información que permita evaluar los procesos de negocios de acuerdo a las expectativas de los usuarios de los mandos táctico-estratégicos debido, al menos, a las siguientes razones:
- Dispersión y duplicación. Los datos necesarios para los reportes se encuentran en diferentes sistemas con sus propias bases de datos, esto dificulta significativamente la elaboración de reportes, en algunas de estas bases de datos hay se guarda información de la misma entidad: el sistema de almacenes y el sistema de ventas duplican información sobre los productos.
- Diferencias de formato y codificación. Atributos de las mismas entidades tienen diferente tipo de dato o codificación en diferentes bases de datos; por ejemplo, en un sistema el género de los clientes se registra como ‘masculino’, ‘femenino’ en otro sistema como ‘H’ y ‘M’
- No mantienen profundidad histórica. El sistema contable al inicio de cada gestión crea un registro con los saldos de las cuentas y elimina las transacciones de la gestión pasada; o el sistema de ventas actualiza la dirección de un cliente, de manera que ya no es posible saber, por ejemplo, que el año pasado sus compras deberán considerarse como ventas en Santa Cruz de la Sierra y que este año sus compras deberán considerarse como ventas en Cochabamba.
En reconocimiento de estas dificultades se hizo evidente la necesidad de contar con un Depósito de Datos, definido como:
Una colección de datos enfocada en el análisis del desempeño de la ejecución de los procesos de negocio, derivada de las fuentes de datos internas y algunas externas, cuyo fin es soportar la toma de decisiones de la organización, no las operaciones de negocio.
Estos sistemas ofrecían las siguientes ventajas respecto de los sistemas de la primera generación:
- Diseño orientado a satisfacer las necesidades consulta de información de los usuarios de negocio, no para soportar el funcionamiento de las aplicaciones operacionales que registrar transacciones durante la operación diaria de la empresa.
- Datos limpios y consistentes almacenados en formato entendible por los usuarios menos técnicos (se evitan códigos en favor nombres).
- Mantenimiento de información histórica y agregada.
- La llegada de los sistemas cliente/servidor posibilitó el desarrollo de interfaces usuario más amigables.
Un Depósito de Datos está diseñado para ser el repositorio único de información para toda la organización. Es importante resaltar que, una vez construido, debe ser la única fuente a la que los usuarios de negocio deben ir buscar información. Aunque esto puede parecer evidente, la experiencia demuestra que no siempre es así.
El primer Almacén de Datos fue creado por Bill Inmon en 1985 para un banco en el estado de Colorado, Estados Unidos.
Tercera Generación: Soluciones de Inteligencia de Negocios
Desarrollados sobre la base de los avances tecnológicos que acompañaron los sistemas de segunda generación como la arquitectura cliente/servidor, motores de bases de datos más potentes y bases de datos centralizadas especialmente diseñadas para la extracción de datos, los Sistemas de Inteligencia de Negocio facilitan el desarrollo de soluciones completas para el cargado, visualización y análisis de datos (reporting, OLAP, tableros de mando).
Los Sistema de Inteligencia de Negocio se centran no sólo en una mejora tecnológica sino principalmente en la provisión de stacks tecnológicos completos que soportan el desarrollo de soluciones de diseño, carga, visualización y análisis de datos. Con los sistemas de segunda generación muchas empresas contaban con Depósitos de Datos infra utilizados debido a la falta de documentación sobre el modelo de datos o debido a que la principal herramienta de acceso los datos eran herramientas basadas en consultas SQL construidas por personal técnico y no por usuarios de negocio.
Los primeros proveedores de software especializado en análisis de datos surgieron en la primera mitad de la década de los 90s.
Macrodatos (Big data) 2000s: Explotación de datos no estructurados a escala masiva y en tiempo real
A inicios de los 2000s, coincidiendo con la explosión de datos no estructurados, el hardware básico (servidores, RAM, discos y unidades flash) también se volvieron baratos y omnipresentes. Varias innovaciones permitieron la computación distribuida y el almacenamiento en clústeres informáticos masivos a gran escala haciendo posible el procesamiento de volúmenes de datos que superaban la capacidad de almacenamiento que podía proveer un dispositivo de almacenamiento. Había comenzado la era del «big data».
Las herramientas de big data de código abierto en el ecosistema de Hadoop maduraron rápidamente y se extendieron desde Silicon Valley a empresas expertas en tecnología en todo el mundo. Por primera vez, cualquier empresa tuvo acceso a las mismas herramientas de datos de vanguardia utilizado por las principales empresas de tecnología. Otra revolución se produjo con la transición de la computación por lotes a la transmisión de eventos, marcando el comienzo de una nueva era de macro datos en «tiempo real».
Herramientas de datos tradicionales orientadas a la empresa y basadas en GUI de repente se sintieron anticuadas y el procesamiento de datos basado en código tomó gran relevancia.
Simplificación del stack tecnológico (2010s): Ingeniería para el ciclo de vida de los datos
A pesar del poder y la sofisticación de las herramientas de big data, administrarlas era mucho trabajo y requería constante atención. Los ingenieros a menudo pasaban demasiado tiempo manteniendo herramientas complicadas en lugar del desarrollo de soluciones para generar valor del negocio.
Los desarrolladores de herramientas y los proveedores de servicios en la nube comenzaron a buscar formas para abstraer, simplificar y facilitar el procesamiento de datos sin incurrir en elevados costos de administración de clústeres dando origen a una nueva generación de herramientas que simplicaron significativamente el stack tecnologico de la ingeniería de datos.
Con mayor abstracción y simplificación, el ingeniero de datos ya no está abrumado con los detalles técnicos de las primeras herramientas para el procesamiento de macro datos y puede enfocarse en cosas más altas en la cadena de valor: seguridad, datos administración, DataOps, arquitectura de datos, modelador de datos, orquestación y gestión del ciclo de vida de los datos.
Inteligencia de Negocios
Inteligencia de Negocios es el uso de datos operacionales y de fuentes externas para facilitar la toma de decisiones basada en comprensión del funcionamiento pasado, actual y estimado de la empresa y su entorno.
Arquitectura
Los sistemas de Inteligencia de Negocios organizan sus componentes principales de acuerdo a la siguiente arquitectura: 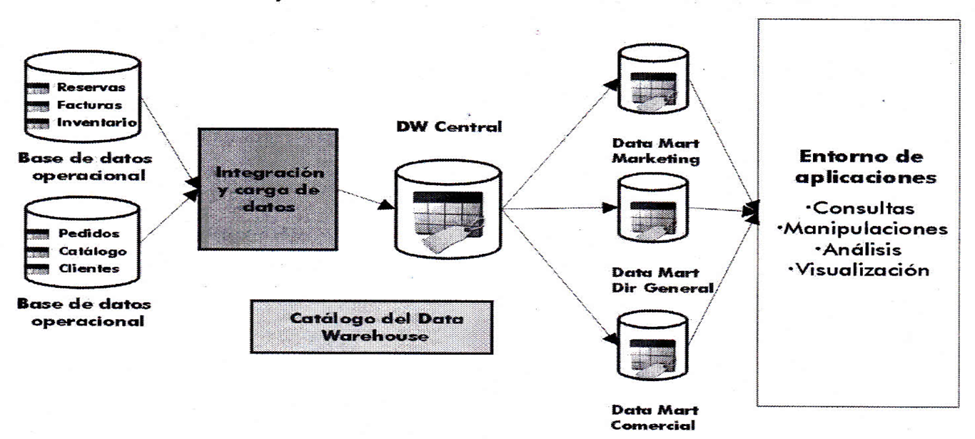
Los diferentes tipos de analítica de datos
La explotación de los datos para apoyar la toma de decisiones en los sistemas de Inteligencia de Negocios puede asumir alguna de las siguientes formas:
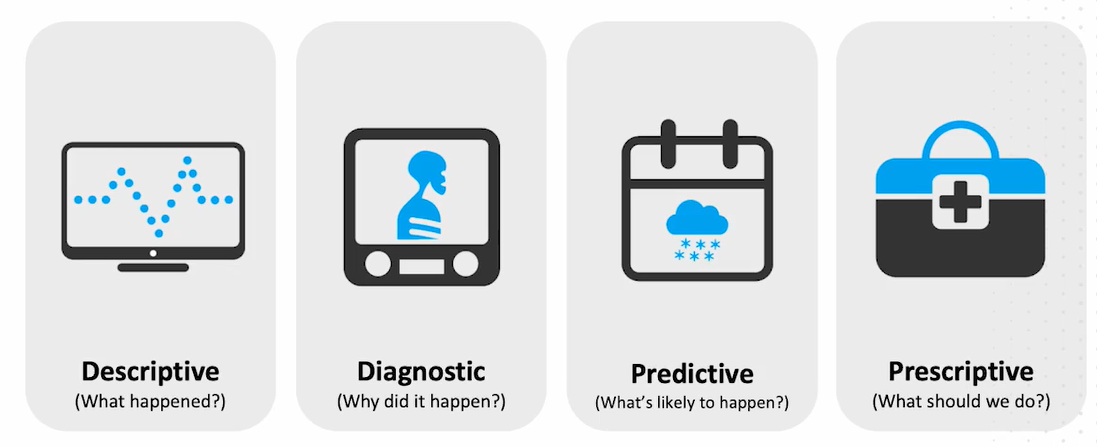
Analítica descriptiva. Agregar y visualizar datos históricos empleando reportes predefinidos y ad hoc para ayudar a la comprensión del estado actual y pasado del negocio.
Analítica diagnóstica. Explorar datos para comprender la causa o el evento detrás de ciertos resultados. Por ejemplo, para el caso de un representante de ventas que terminó cerrando menos ventas de lo usual, un desglose podría mostrar menos días de trabajo porque estaba de vacaciones.
Técnicas como el desglose (drill down), la identificación de correlaciones o las alertas son típicas de este tipo de analítica.
Analítica predictiva. Uso de datos del depósito de datos, algoritmos estadísticos y técnicas de aprendizaje automático para identificar la probabilidad de resultados futuros basados en datos históricos. La creación de modelos predictivos aplicando aprendizaje automático y modelado estadístico son el propósito de la analítica predictiva.
Analítica prescriptiva. Emplea datos históricos (descriptiva) y estimados (predictiva) para ofrecer recomendaciones sobre las acciones óptimas para lograr los objetivos del negocio, como la satisfacción del cliente, incremento de beneficios o reducción de costos. Técnicas de simulación y optimización son fundamentales en este tipo de analítica.
¿Por qué son necesarios los Sistemas de Inteligencia de Negocios?
La necesidad de contar con información de calidad[1] del negocio
La información en una organización se construye a partir de los datos generados principalmente en dos fuentes: 1) el sistema transaccional que registra y soporta la operativa diaria de la organización y 2) fuentes externas, que dependiendo del sector de actuación podrían llegar representar un porcentaje significativo de la totalidad de fuentes de datos disponibles.
A la hora de generar información a partir de las diversas fuentes de datos, una organización debe lidiar con las siguientes dificultades:
- La sobreabundancia de datos. La capacidad de procesar datos se ve superada por volúmenes cada vez mayores de datos.
- Datos dispersos en fuentes y repositorios heterogéneos.
- Los datos no están organizados de manera tal que facilite la generación de información para los mandos táctico-estratégicos (Por ejemplo, en muchos casos no se preserva los cambios históricos).
Las nuevas exigencias del mercado
Cambio de una orientación al producto hacia una orientación al mercado.
Ya no es suficiente analizar únicamente el desempeño interno y ahora es también necesario comparar el desempeño propio con el resto de los proveedores del mercado con el objetivo de buscar el mejor desempeño del sector a través de mejoras en áreas como:
- Una mejor rentabilidad,
- Mayor rapidez en el ciclo de vida de desarrollo del producto o servicio
- Mayor innovación en los productos y servicios
- Facilitar el acceso de los consumidores a los productos y servicios.
Para poder comparar el desempeño propio en estos y otros aspecto con la competencia, será necesario incorporar datos de fuentes externas. Este acercamiento entre datos externos e internos no es una tarea sencilla.
Personalización
El siguiente cuadro resume las características de los productos y servicios que el mercado ha venido demandando en las últimas décadas.
| Periodo | Característica diferenciadora |
| Postguerra | Precio |
| 70s | Calidad |
| 80s | Tiempo, especialmente crítico en los servicios |
| 90s | Servicios asociados (servicio técnico, garantías, plazo entrega, etc.) |
| 2000s | Personalización, oferta de servicios/productos en consideración del perfil de cada cliente. |
Descubrir los patrones y tendencias de consumo de segmentos de clientes cada vez más específicos es fundamental para anticipar futuros comportamientos y poder:
- Aumentar el rendimiento de acciones comerciales y marketing
- Afinar la propuesta de servicios
- Mantener la fidelidad de los clientes.
Inteligencia Operativa
La inteligencia operativa busca proveer información de calidad al nivel operativo para tomar el mejor curso de acción en tareas cotidianas como el servicio al cliente o monitoreo de aplicaciones. Típicamente, implica la integración de datos del Depósito de Datos con datos generados en tiempo real.
[1] Información completa, confiable y oportuna.
Comments are closed.