Modelo de Datos Dimensional
Un modelo de datos es una herramienta empleada para describir, razonar y tomar decisiones sobre los datos y sus relaciones en determinada área de interés. Dependiendo del nivel de abstracción un modelo de datos puede ser:
- Modelo de datos Conceptual, centrada en los datos y sus relaciones independientemente de la tecnología empleada para su implementación.
- Modelo de datos Lógico, centrada en los datos y sus relaciones en consideración de las estructuras de datos de la tecnología empleada para su implementación.
El modelo de datos dimensional es un modelo conceptual que organiza los datos resultantes de la ejecución de un proceso de negocio en dos tipos de entidades relacionadas entre sí: medidas y dimensiones.
Las medidas son datos numéricos que pueden ser manipulados por operaciones tales como: suma, promedio, máximo, mínimo, desviación estándar, conteo, etc. Por ejemplo, una venta produce al menos un par de medidas interesantes: el importe de la venta y la cantidad de productos vendidos.
Las dimensiones son datos sobre el contexto en el cuál fueron generadas las medidas; usualmente describen cuándo, dónde, quién, cómo y qué generó la medida. Por ejemplo, en el caso de una venta, esta:
- Ocurre en una fecha,
- Se realiza en una tienda,
- Implica la participación de un vendedor y un comprador
- Se paga en efectivo o mediante tarjeta; en Bs. USD o EUR
- Hace referencia al objeto de la venta; es decir, algún producto o servicio.
La relación entre una medida y sus dimensiones es usualmente de uno a muchos desde la dimensión hacia la medida; por ejemplo, en una misma fecha puede realizarse varias ventas, pero una venta se realiza en una fecha.
Es importante mencionar que es el rol del dato, más que su tipo, lo que determina su uso como dimensión o medida; por ejemplo, el salario del cliente es un valor numérico pero no es una medida generada por el proceso de venta; sin embargo, se podría emplear para analizar el importe total de ventas según el rango salarial del cliente.
A lo largo de más de tres décadas, el Modelo de Datos Dimensional ha demostrado su efectividad para organizar los datos con propósito de análisis porque satisface dos requerimientos críticos de los Sistemas de Inteligencia de Negocios:
- Organizar los datos en términos comprensibles para los usuarios del nivel táctico-estratégico
- Flexibilidad y buen desempeño en la consulta de grandes volúmenes de datos. Con los datos organizados en medidas relacionadas con sus dimensiones es posible analizar la medidas en términos de cualquier combinación de dimensiones; por ejemplo, total ventas por fecha y cliente, cantidad productos por tipo de productos y forma de pago, etc.
Finalmente, para documentar los modelos de datos dimensionales se suele utilizar la notación de los diagramas E-R.
Medidas aditivas, no-aditivas y semi-aditivas
Dependiendo de si los valores de una medida pueden o no ser sumadas para diferentes valores una dimensión, las medidas se clasifican en medidas aditivas, no-aditivas y semi-aditivas.
Medidas aditivas
Una medida es aditiva cuando valores asociados a distintos eventos pueden sumarse para cualquier rango de valores de cualquier dimensión. Ejemplo, el importe de una venta es aditiva porque es posible obtener sumas totales por fecha, tienda, cliente, tipo de moneda, forma de pago o producto.
Medidas no-aditivas
Una medida es no-aditiva cuando valores asociados a distintos eventos no pueden sumarse para ningún rango de valores de cualquier dimensión. Ejemplo, el importe promedio de una venta no es aditiva porque no es posible sumar los importes promedios por fecha, tienda, cliente, tipo de moneda, forma de pago o producto para obtener el importe promedio total.
Esta es una característica típica de los porcentajes y ratios; en estos casos, siempre que sea posible, es mejor incluir las medidas aditivas que se emplean para calcular la medida no-aditiva.
Medidas semi-aditivas
Una medida es semi-aditiva cuando valores asociados a distintos eventos no pueden sumarse para un rango de valores de alguna dimensión. Ejemplo, el balance de una cuenta bancaria no es aditiva en la dimensión tiempo: si balance diario durante la última semana es 100 Bs, esto no significa que mi balance al final de la semana es 700 Bs.
Esta es una característica típica de los porcentajes y ratios; en estos casos, siempre que sea posible, es mejor incluir las medidas aditivas que se emplean para calcular la métrica.
Nivel de detalle (Grain)
El nivel de detalle al cual van a ser tomadas las medidas generadas por un proceso está determinada por el máximo nivel de detalle de las dimensiones asociadas; es aceptable que un mismo proceso pueda ser medido con diferente nivel de detalle en función de los requerimientos de análisis de diferentes perfiles de usuario.
Por ejemplo, el proceso “depósitos en cajas de ahorro” genera la media “importe” y esta puede ser analizada a diferente nivel de detalle:
1) Importe por cliente, cuenta, operación y fecha
2) Importe por cliente, cuenta y fecha
En el primer caso, cada evento de depósito genera un medida; en el segundo escenario, todos los depósitos realizados en el mismo día, por el mismo cliente y en la misma cuenta, son resumidos en una única medida; es decir, si el cliente hizo dos depósitos de 100 y 50 Bs. Se generaría una medida equivalente a un único depósito de 150 Bs.
En general, un modelo dimensional debería preservar el máximo nivel detalle o nivel de detalle transaccional para poder satisfacer la mayor cantidad de requerimientos de análisis.
Estrellas y Cubos
Los datos de un modelo dimensional pueden ser almacenados en dos tipos de estructuras: tablas en una Base de Datos Relacional o cubos en una Base de Datos Dimensional. Cuando se almacenan en una Base de Datos Relacional el esquema tiene forma de estrella con las métricas almacenadas en un tabla de hecho y las dimensiones almacenadas en tablas de dimensión y relaciones que van desde la tabla de hechos hacia las tablas de dimensión; los datos se obtienen ejecutando consultas SQL. En las Bases de Datos Dimensionales, los valores de las medidas se encuentran al intersectar valores de los ejes de un espacio dimensional, cada dimensión define un eje con los valores de la dimensión como puntos de intersección en el eje asociado, los datos se obtienen ejecutando consultas MDX.
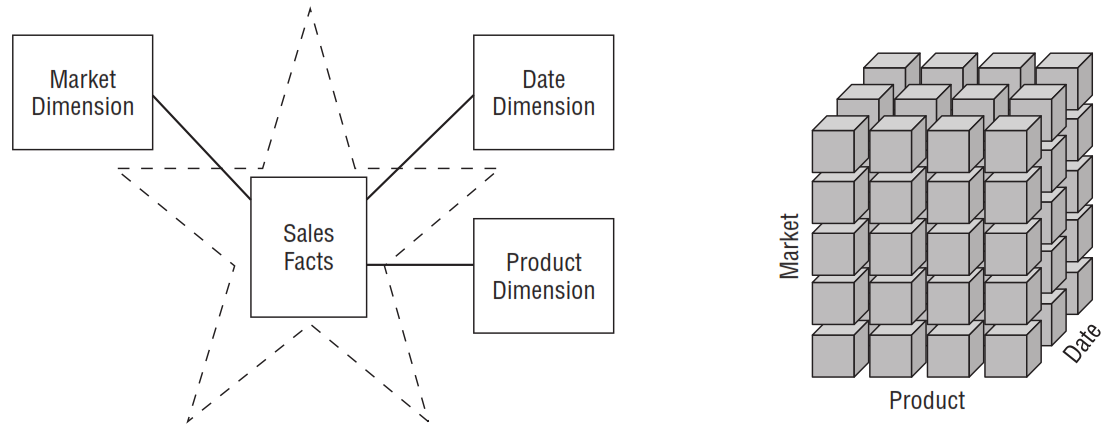
[1]
Las Bases de Datos Dimensionales organizan los datos en estructuras que facilitan el análisis exploratorio mediante operaciones iterativas de profundización-agregación, filtrado y pivotado. Históricamente, las Bases de Datos Dimensionales se han caracterizado por tener tiempos de respuesta menores que sus contrapartes relacionales, sin embargo, con la aparición Bases de Datos Relacionales Columnares y la posibilidad de mantener bases de datos en memoria estas diferencias se han reducido al punto de ser prácticamente inexistentes. Por otro lado, las Bases de Datos dimensionales se almacenan en archivos de formato propietario lo cual dificulta considerablemente cambiar el proveedor de la BD dimensional provocando el temido vendor lock-in[2].
En la práctica, en consideración de: 1) la amplia aceptación de las Bases de Datos Relacionales en la industria más la estandarización del lenguaje de consulta SQL y 2) la potencia analítica de las Bases de Datos Dimensionales, se suele emplear un enfoque en el cual ambas tecnologías se usan de manera complementaria. Un esquema muy empleado para este propósito se conoce como ROLAP. Un sistema ROLAP implementa una Base de Datos dimensional capaz de procesar consultas dimensionales, usualmente escritas en lenguaje MDX, que internamente se traducen a consultas a una Base de Datos Relacional en lenguaje SQL, las respuesta de la BD Relacional se transforman a su vez en respuesta de tipo dimensional. Este tipo de sistema supone las siguientes ventajas:
- A diferencia de las Bases de Datos Dimensionales nativas (MOLAP), una Base de Datos Dimensional ROLAP tiene siempre los datos tan actualizados como los de la BD relacional que consulta, porque no es necesario ejecutar un proceso de carga y procesamiento desde BDs relacionales, usualmente necesario en sistemas MOLAP
- En la misma instalación/despliegue, se dispone de un modelo dimensional en los dos tipos de almacenamiento de manera tal que al momento de desarrollar aplicaciones analíticas se tienen más opciones a la hora de extraer los datos para su posterior análisis y/o visualización.
En futuros artículos se mostrará como desplegar y poner en marcha un sistema ROLAP empleando herramientas Open Source.
[1] Fuente: The Data Warehouse Toolkit, Third Edition.
[2] Temido por los clientes no los proveedores, obviamente.